Equipos Lentos o Inestables Guía Profesional para Diagnosticar y Corregir Fallas de Hardware Comunes
En el entorno empresarial moderno, donde la eficiencia depende cada vez más de la infraestructura tecnológica, los problemas de rendimiento en equipos informáticos pueden representar pérdidas considerables de productividad, aumento en los costos operativos y disminución en la calidad del servicio. Según un estudio de IDC (2024), las interrupciones por fallas de hardware generan más de $4.600 millones en pérdidas anuales a nivel global, especialmente en pymes y sectores administrativos.
A menudo, los síntomas como lentitud excesiva, bloqueos repentinos, sobrecalentamiento o errores de lectura de disco son señales de fallas de hardware subyacentes. Estos problemas, si no se detectan y corrigen a tiempo, pueden desencadenar daños mayores o pérdida de datos críticos.
Comprendiendo los Síntomas de Problemas de Hardware
Los problemas de rendimiento pueden tener múltiples orígenes, por lo que el primer paso es una observación sistemática de los síntomas:
| Síntoma | Posible origen |
| Lentitud general del sistema | Disco duro degradado, RAM insuficiente |
| Pantalla azul (BSOD) | Error de memoria, controlador defectuoso |
| Reinicios aleatorios | Fuente de poder inestable, sobrecalentamiento |
| Ruido inusual o clics en el equipo | Fallo mecánico del disco duro |
| Congelamientos frecuentes | Overheating de CPU o GPU, RAM dañada |
| Pérdida de archivos o errores de lectura | Sectores dañados en el disco |
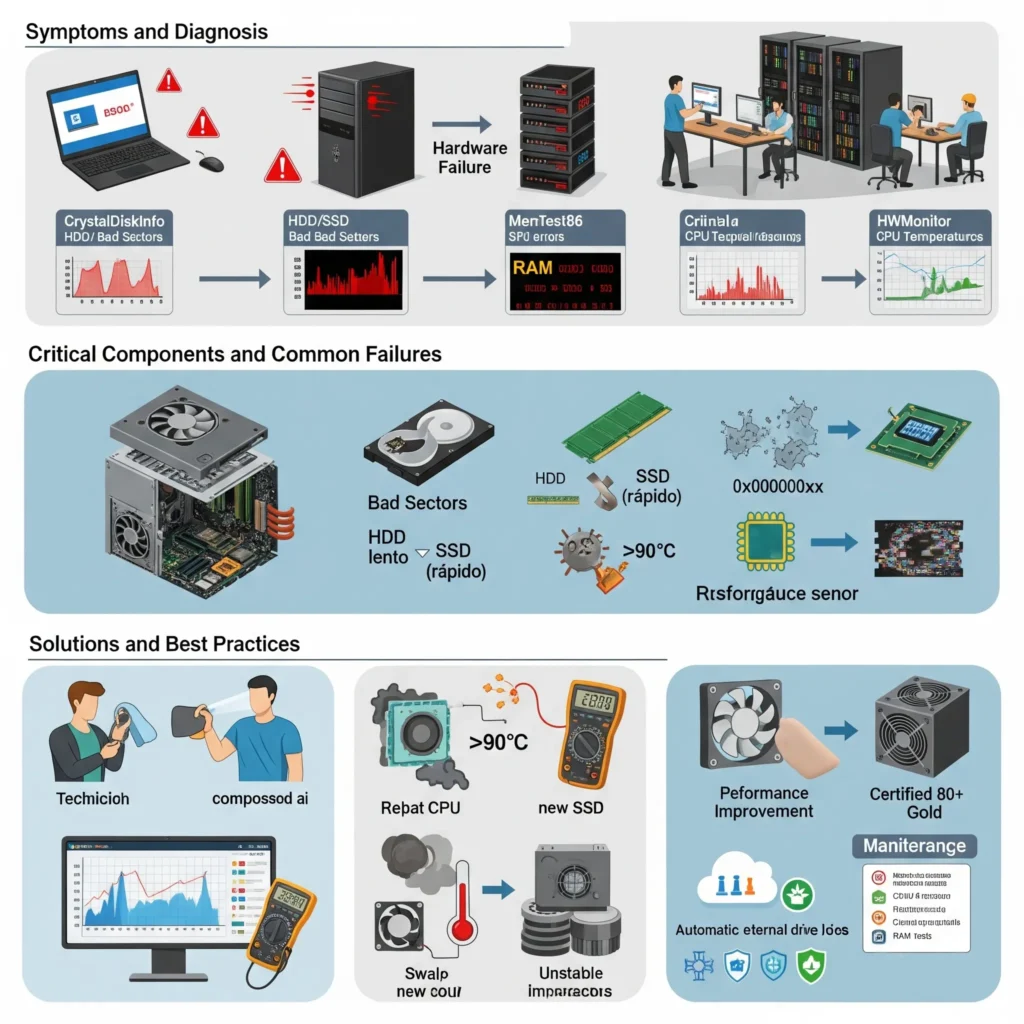
Herramientas clave para la detección inicial:
- Administrador de tareas (Windows) / Monitor de actividad (macOS) / top, htop (Linux) para ver uso de recursos.
- CrystalDiskInfo, Hard Disk Sentinel para verificar salud de discos.
- MemTest86 para test de RAM.
- HWMonitor, Speccy, o Open Hardware Monitor para verificar temperaturas.
Diagnóstico de Fallas Comunes por Componente
Disco Duro o SSD
Problemas comunes:
- Sectores defectuosos (bad sectors).
- Tiempos de respuesta lentos.
- Fallas en controladores del SSD.
Cómo detectar:
- Usar SMART diagnostics (CrystalDiskInfo, GSmartControl).
- Verificar con CHKDSK (Windows) o fsck (Linux).
Soluciones recomendadas:
- Backup inmediato si se detectan errores graves.
- Cambiar el disco por uno nuevo (preferentemente SSD NVMe).
- Actualizar firmware del SSD si es necesario.
Memoria RAM
Problemas comunes:
- Códigos de error de memoria (0x000000xx).
- Fallos al ejecutar múltiples programas.
- Reinicios inesperados.
Cómo detectar:
- Ejecutar MemTest86 desde una USB.
- Revisión por módulos: probar uno a uno si hay múltiples.
Soluciones recomendadas:
- Reemplazo del módulo defectuoso.
- Verificación de compatibilidad con la placa madre (frecuencia, latencia).
Procesador (CPU)
Problemas comunes:
- Temperaturas elevadas (más de 90 °C bajo carga).
- Lentitud en procesos intensivos.
- Bloqueos aleatorios.
Cómo detectar:
- Monitorear con HWMonitor, Core Temp o Ryzen Master.
- Evaluar en pruebas de estrés con Prime95 o Cinebench.
Soluciones recomendadas:
- Limpieza de ventilador y cambio de pasta térmica.
- Reemplazo del disipador por uno de mejor rendimiento.
- Verificación del voltaje en BIOS o UEFI.
Tarjeta Gráfica (GPU)
Problemas comunes:
- Artifacts gráficos (píxeles defectuosos, líneas).
- Cuadro congelado durante carga gráfica.
- Cierre inesperado de aplicaciones 3D.
Cómo detectar:
- Pruebas con FurMark o Unigine Heaven Benchmark.
- Verificar temperatura con MSI Afterburner.
Soluciones recomendadas:
- Desmontaje y limpieza.
- Actualización de drivers o rollback si el problema aparece tras actualizar.
- Reemplazo si presenta fallos crónicos de hardware.
Fuente de Poder (PSU)
Problemas comunes:
- Reinicios repentinos sin patrón.
- Dispositivos no reciben energía estable.
- Ruido eléctrico o sobrecalentamiento.
Cómo detectar:
- Pruebas con multímetro (voltajes: +12V, +5V, +3.3V).
- Uso de testers de PSU especializados.
Soluciones recomendadas:
- Sustitución por fuente certificada 80 PLUS.
- Evitar sobrecargas de energía con regletas básicas.
Procedimientos de Diagnóstico Profesional
Inspección Visual y Limpieza Interna
Una revisión visual con linterna puede revelar:
- Polvo acumulado en ventiladores.
- Capacitores hinchados.
- Placas manchadas por humedad.
Recomendación técnica:
Realizar limpieza con aire comprimido cada 4–6 meses y cambio de pasta térmica anualmente en estaciones de trabajo intensivas.
Pruebas de estrés y benchmarking
Herramientas como OCCT, AIDA64, Cinebench, PassMark, entre otras, ayudan a forzar los componentes y revelar inestabilidades no visibles durante un uso convencional.
Verificación de compatibilidad y firmware
Muchas fallas son causadas por incompatibilidades de BIOS, firmware desactualizado o controladores mal instalados. Verificar versiones directamente desde los sitios oficiales del fabricante.
Prevención: Mantenimiento Predictivo y Buenas Prácticas
Monitoreo constante
Instalar herramientas de monitoreo en segundo plano permite:
- Identificar incrementos de temperatura peligrosos.
- Detectar patrones de uso excesivo de CPU o disco.
Rutinas programadas
- Escaneos SMART automáticos cada 30 días.
- Test de RAM cada 6 meses.
- Backup automatizado en nubes privadas o discos externos.
Capacitación del usuario
La prevención empieza por el uso correcto. Capacitar al personal para evitar:
- Sobrecargas por multitarea innecesaria.
- Descargas de software no verificado.
- Conexión de periféricos defectuosos.
Escenarios de Fallas Reales y Resoluciones
Caso 1 – Laptop administrativa con lentitud extrema
Síntoma: 15 minutos para iniciar, aplicaciones colapsan.
Diagnóstico: Disco HDD con 24% de sectores reubicados (CrystalDiskInfo).
Solución: Reemplazo por SSD NVMe de 512GB. Mejoró arranque a 30 segundos.
Costo estimado: $45 USD.
Caso 2 – PC de diseño gráfico con cierres inesperados
Síntoma: Apagados repentinos al abrir Photoshop o Premiere.
Diagnóstico: Fuente de poder genérica de 450W, temperatura de GPU 95 °C.
Solución: Cambio a PSU 650W certificada y limpieza de disipador GPU.
Resultado: Estabilidad completa y mejora del 20% en rendimiento.
Caso 3 – Estación de trabajo con pantallazos azules constantes
Síntoma: BSOD con código “MEMORY_MANAGEMENT”.
Diagnóstico: MemTest86 detectó errores en módulo RAM.
Solución: Reemplazo por módulos Kingston DDR4 nuevos.
Resultado: Estabilidad total en sesiones largas.
Tecnología de Apoyo en Diagnóstico Corporativo (2025)
- IA Predictiva en Mantenimiento: Soluciones como Atera, Domotz y NinjaOne ofrecen detección automática de fallas antes que afecten al usuario.
- UEM (Unified Endpoint Management): Herramientas como Microsoft Intune permiten gestionar remotamente el estado de hardware en flotas completas.
- Sensores IoT en Servidores: Detectan condiciones críticas (temperatura, humedad) para activar protocolos de protección automática.
Los problemas de hardware son inevitables, pero su impacto puede minimizarse sustancialmente con un enfoque técnico proactivo. Detectar y resolver las fallas antes de que afecten al usuario final no solo evita pérdidas, sino que prolonga la vida útil del equipo y mejora la experiencia operativa.Las empresas que adoptan rutinas de diagnóstico preventivo, capacitan a su personal y utilizan tecnología de monitoreo inteligente estarán mejor preparadas para garantizar infraestructura confiable, eficiente y lista para los retos del futuro digital.
- Cómo mejorar la estabilidad y seguridad de la red informática empresarial
- 10 errores tecnológicos en empresas que generan pérdidas y cómo evitarlos
- ¿Se pueden recuperar archivos eliminados de un disco duro o SSD? Guía de recuperación de datos para empresas
- Informática Forense Empresarial: Qué es y Cuándo una Empresa Necesita un Análisis Digital
- Cómo proteger la información de tu empresa y evitar la pérdida de datos